
モデルとデータを見直して、Bird Classification の精度を改善した話

目次
迷惑メールが多すぎます。
この記事は、社内イベント「お茶会」での発表内容をもとにまとめたものです。
今回は弊社の arakawa が「Bird Classification の精度改善」について話しました。
社内で制作した鳥類分類のデモアプリ「Bird Classification」の精度を、日頃からちょこちょこ試しています。
ある日、ネットで拾ったヤマガラの写真を、試しに Bird Classification に読み込ませてみました。
どう見てもヤマガラの写真だったので当然正しく判定されると思っていたのですが、返ってきた結果はまさかのジョウビタキ♂。
確かに、角度によってはジョウビタキ(特にオス)もお腹が橙色で、頭部に黒い柄があるので、一部分の特徴だけを捉えると似て見えることもあります。とはいえ、背中の色味や全体のシルエットまで含めて判断すれば、両者は明らかに別の鳥です。
それを判定できなかったことに、正直ショックを受けました。
そして、この事件をきっかけに「どうにかして分類の精度をもっと上げたい」と思うようになりました。
01 Bird Classification とは
Bird Classification は、ニューラルネットを利用した技術検証プロジェクトとして、社内で開発した野鳥画像の分類アプリです。
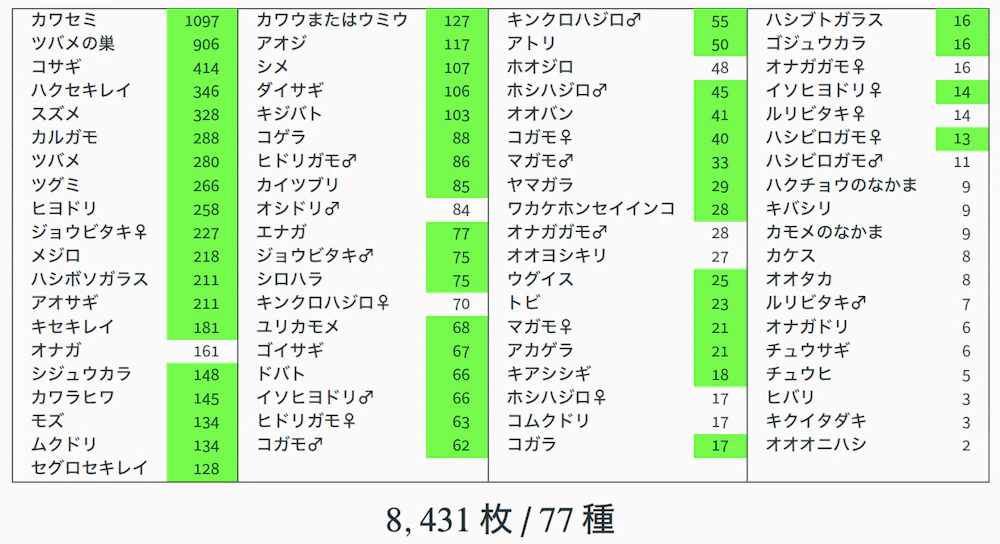
私が個人的に撮影してきた写真の中から、6,310 枚・77 種の画像を学習データとしており、ブラウザ上で写真をアップロードすることで、鳥の種類を推定することができます。
Bird Classification について、詳しくはこちらの記事をご覧ください。
02 ニューラルネットによる画像分類
ニューラルネットの精度を上げる方法を考える前に、まずはニューラルネットによる画像分類がどのように動いているのかを簡単におさらいしておきましょう。
ニューラルネットは、ニューロンと呼ばれる多入力一出力の非線形関数を、層状に束ねて結線したものです。
ニューロンの内部には重みと呼ばれるパラメーターがあり、入力値に応じて計算を行い、出力を次のニューロンへ渡していきます。
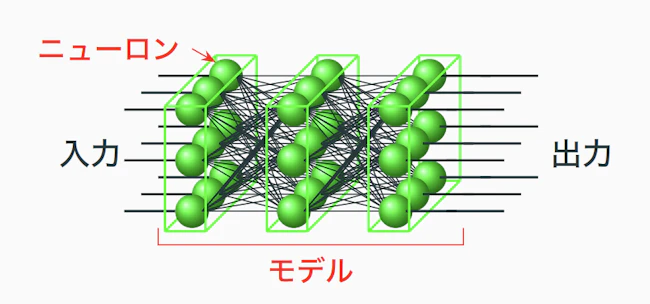
ニューロンの結線方法は、やたらに繋げばいいわけではありません。
層の数や結線の仕方を工夫する必要があり、こうした構成全体(コンフィギュレーション)をモデルと呼びます。
画像分類の場合は、画像のビットマップデータ(224×224ピクセル)を入力し、ネットワークの各層を順に通るなかで特徴が取り出されていきます。
最終的な出力層は、分類対象ごとにニューロンを用意しておき、その中で最も大きい値となったものを判定結果として扱う仕組みです。
ニューラルネットが正しい判定をできるようにするには、学習が必要です。学習では、データを与えたときの出力と正解との誤差をもとに、バックプロパゲーションというアルゴリズムで各ニューロンのパラメーター(重み)を修正していきます。
この更新を繰り返すことで、ネットワークが徐々に正しい出力に近づくようになるのです。
学習のさせ方
ニューラルネットで画像分類を行うときは、まず学習用データの一覧表を作る必要があります。

この一覧表づくりが意外と手間で、
- ファイル名
- 正解の種類
- 画像を正方形に切り出すときの位置(中央・左など。今回補助的に入れたもの)
といった情報を、ひとつひとつ書いてまとめていきます。
学習に使うデータはすべてを使うのではなく、だいたい 2 割程度を評価用データとして残しておくのが一般的です。
ちなみに評価用データは、学習には絶対に使ってはいけません。これは「学習で見たことがない画像で正しく判断できるか」を確かめるためです。
学習の流れはシンプルで、
- 学習用データを使ってニューラルネットのパラメーターを更新
- 1 エポック(学習の1巡)が終わるごとに、評価用データで正答率を計算する
これを繰り返します。
すべてのエポックの中で最も正答率が高かった時点の重みを、最終的な結果とします。
実際の学習で見えてきた課題
実際に Bird Classification のデータで学習を回してみると、いくつか気になる点が出てきました。
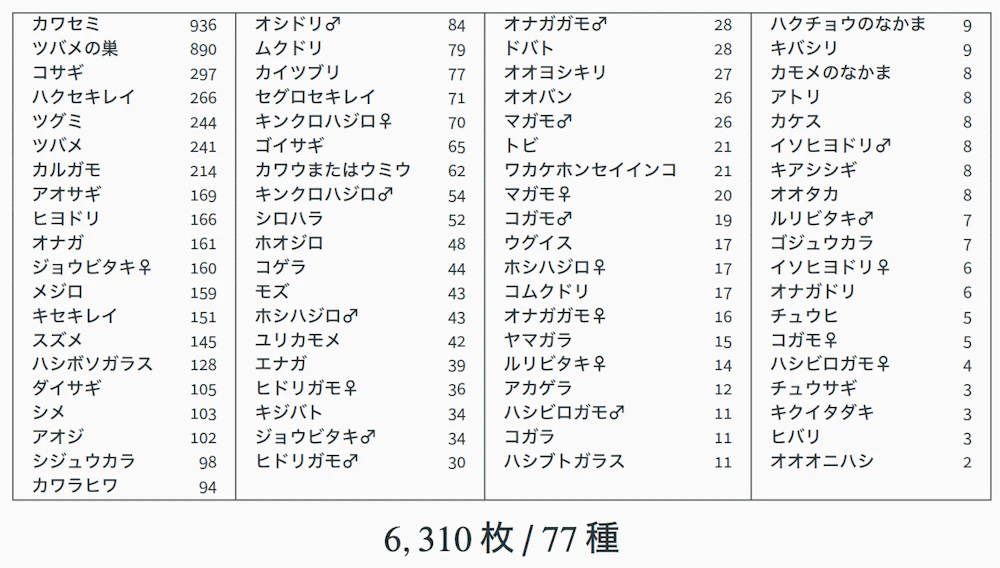
まず、今回の誤判定の原因になったヤマガラの学習枚数が 15 枚しかなかったことです。
これではさすがに厳しい面もありますが、とはいえ何とかして判定できるようにしたいところ。
さらに、全体の6,310枚という枚数も、画像分類のタスクとしては多いとは言えません。
少ないデータをなんとか補うために、別のデータセットで事前に学習された重みを使ってスタートするファインチューニングの手法(少ない枚数でも成果が出やすい方法)をとりましたが、それでも限界がありました。
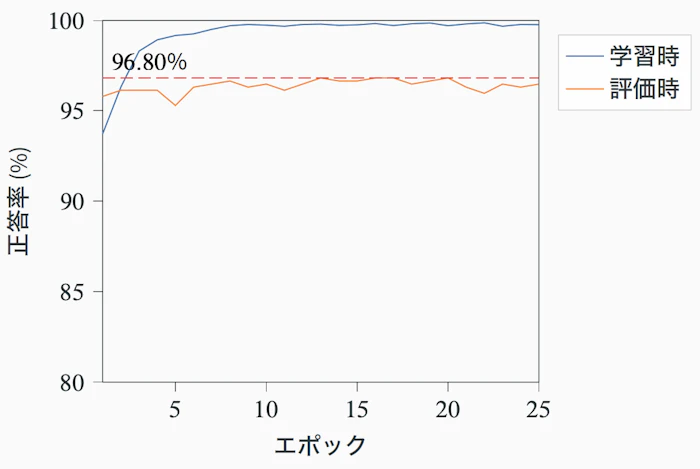
25 エポック学習させた結果、学習用データに対する正答率は順調に上がるものの、評価用データの正答率は点線のあたりで頭打ちになり、なかなか伸びていきませんでした。
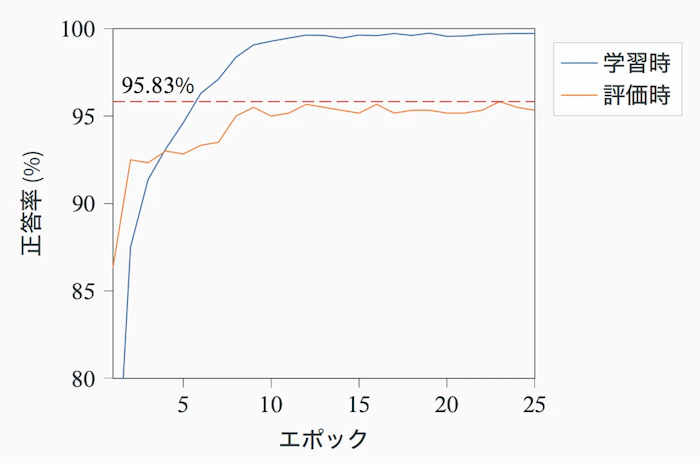
これは学習が進むほど、モデルが「写真そのものを覚えてしまっている」状態(過学習)になってしまい、本来重要である「未知の画像」に対して良い結果が出せなくなっていたためです。
03 精度を上げるには
分類の精度を上げる方法は大きく分けて次の二つが考えられます。
- 学習させるデータを増やす
- モデルそのものを高性能なものに置き換える
最も確実なのは 1 の「データを増やす」方法ですが、これは撮影・整理・一覧化を含めてとにかく手間がかかります。
現実的にはかなりしんどく、すぐには対応できません。
一方で 2 の「モデルを置き換える」方法は、計算機を動かして学習を回すだけで試せるため、比較的取り組みやすい手段です。
今回はこのモデルを高性能なものへ置き換えるアプローチを試してみることにしました。
試したモデルとその結果
従来の Bird Classification で使っていたモデル はGoogle が公開している EfficientNet でした。
事前学習済みデータとして efficientnet-b7 を使用しており、そのサイズは 257,621,231 byte とかなり大きなモデルです。
今回はこの従来モデルの精度を超えることを目標に、timm に登録されているさまざまなモデルを試してみることにしました。timm とは幅広い画像分類モデルがまとまっており、比較検証が非常にしやすいライブラリです。
今回試したのは以下のモデルです。
- EfficientNet V2
- efficientnetv2_rw_m.agc_in1k
- efficientnetv2_rw_s.ra2_in1k
- tf_efficientnetv2_l.in21k_ft_in1k
- tf_efficientnetv2_m.in21k_ft_in1k
- tf_efficientnetv2_xl.in21k_ft_in1k
- CoAtNet
- coatnet_0_rw_224.sw_in1k
- coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k
- MambaOut
- mambaout_femto.in1k
ここ数年は、従来の「畳み込みニューラルネット(CNN)」だけでなく、LLM の流れから派生したより大規模なニューラルネットの性能が非常に高く、その系統に属するのが CoAtNet です。
CoAtNet は畳み込みとビジョントランスフォーマーを組み合わせたハイブリッド構造になっており、今回も大きな期待を持って試しました。
しかし、これらのモデルを使っても 未知のデータで精度が伸び悩み、正答率が 95% を超えるところまで届かず。
もう一度 EfficientNet を試してみることに
そこで、一度原点に戻りEfficientNet を再度試す方針をとりました。
ただし今回は、従来とは異なる事前学習データを使っています。
- 事前学習データ:efficientnet_el.ra_in1k
- モデルサイズ:従来の約 1/7(37,203,003 byte)
- 入力サイズ:256×256 pixel
この構成で学習させたところ、正答率 96.13% という今までで最高の結果を得ることができました。
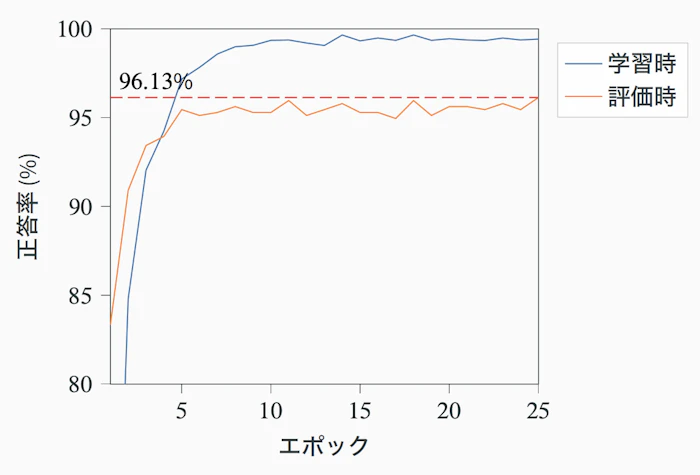
そして問題のヤマガラを判定してみたところ、今度はしっかり正しく分類できました。
もっと精度を上げたい
こうなると欲が出てきます。もっと精度を上げたい。
そこで、2021 年 6 月以降に撮り溜めていた 2,281 枚 の写真を使って、“学習データを増やす” 方向で再挑戦することに。
追加分すべてにラベル付けを行い、一覧表も作り直しています。
その結果、
- 種類は従来より 11 種増加
- ヤマガラの枚数は 15 枚 → 29 枚に増加
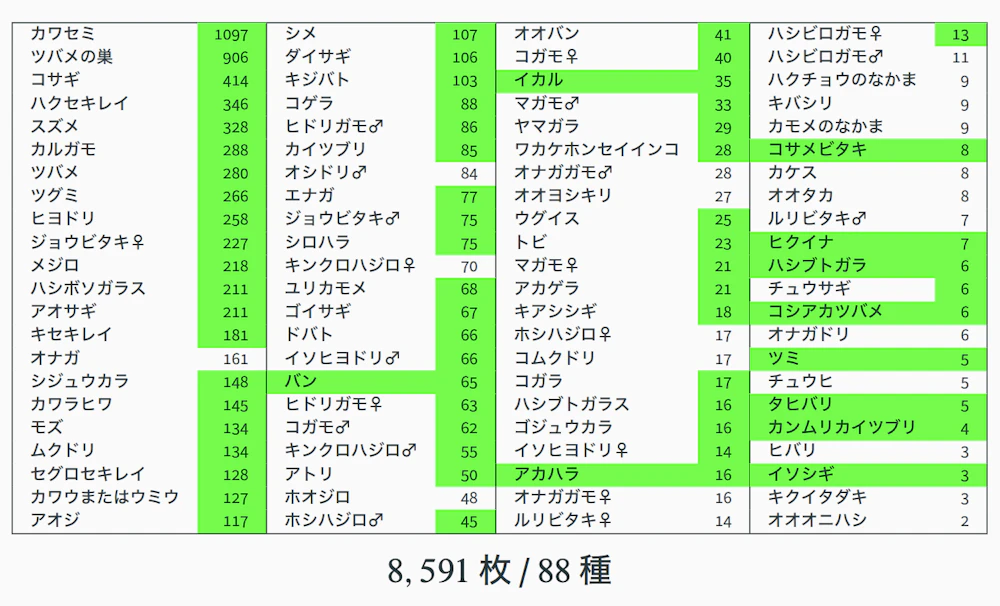
データ量としては十分に増え、「これなら精度も上がるだろう」と期待したのですが、学習させてみると、正答率は 93.03% に下がる結果に。
なぜこんなことが起きたのかを考えたところ、「種が増えたせいで、相対的に 1 種類あたりのデータ量が不足したのではないか?」という可能性が見えてきました。
そこで、泣く泣く新しく増やした11種をいったん外し(画像枚数も8,431 枚に)、従来と同じ種構成に戻して学習をやり直したところ、正答率は 96.8% に到達し、これまでで最高の数字になりました。
04 まとめ
今回のアップデートでは、モデルの差し替えやデータ量の調整など、いくつかの検証を重ねながら Bird Classification の精度改善に取り組みました。
思ったように精度が伸びないケースもあれば、条件を変えた途端にうまくいく場面もあり、単純に「最新モデルに変えれば精度が上がる」という話でもないことが確認できました。
また、データを増やしたからといって必ず性能が向上するわけではなく、種数や構成とのバランスが意外と影響する、という点も今回の作業で改めて実感したところです。
最終的には 96% 台まで精度が向上し、課題になっていた種も正しく分類できるようになりましたが、それ以上に、条件を変えながら確かめていく中で、結果が動くポイントがいくつか見えてきました。
こうした検証は、Bird Classification に限らず、今後なにか画像分類を試すときにも役に立つはずです。
条件を少しずつ変えながら試していくプロセス自体に、得られるものが多いことを再確認する機会になりました。
引き続き、こうした検証の積み重ねを通して、よりよい仕組みやサービスづくりにつなげていきたいと思います。
05 今回の取り組みが活かせる場面
精度改善のプロセスやモデルは、Bird Classification 以外の場面にも応用できます。
たとえば、 弊社の野鳥特化モデルを使って、Web 上の野鳥図鑑に自動識別の機能を追加するといったことも可能です。
また、同程度の学習データが揃えられるのであれば、対象を野鳥以外に置き換えて再学習させることもできます。
一方で、独自モデルをサーバーで運用する場合はインフラコストが発生するため、要件によってはネイティブアプリ化してエッジ AI で動かす構成も選択肢に入ります。利用環境や目的に合わせて、最適な動かし方を設計できます。
分類機能の導入やモデル活用をご検討の際は、今回得た知見も踏まえてご相談をお受けできますので、まずはお気軽にお問い合わせください。

S2ファクトリー株式会社
様々な分野のスペシャリストが集まり、Webサイトやスマートフォンアプリの企画・設計から制作、システム開発、インフラ構築・運用などの業務を行っているウェブ制作会社です。
実績



案件のご依頼、ご相談、その他ご質問はこちらからお問い合わせください。





